728x90
반응형
구글의 오픈 모델 젬마(Gemma) 를 이용하여 PC(로컬)에서 Ollama, Gradio Chatbot interface 를 띄워보기
o PC에 선 설치되있어야 하는 프로그램 (아래 사이트에서 다운도드 및 설치)
- Poetry https://python-poetry.org/
- Ollama https://ollama.com
- Vitual Studio Code https://code.visualstudio.com/
Poetry로 가상환경 생성
# 내 PC의 가상환경 기본 ROOT는 C:\Users\shi1m\Edu> 이다 (본인 환경에 맞게 설치하면됨)
# gemma-gradio-chatbot 프로젝트 가상환경 환경 생성
# C:\Users\shi1m\Edu>poetry new gemma-gradio-chatbot
Created package gemma_gradio_chatbot in gemma-gradio-chatbot
# 관련 패키지 (langchain gradio) / pyproject.tmol에서 확인
# C:\Users\shi1m\Edu>poetry add langchain gradio
# 프로젝트 가상환경 환경 생성후 Vitual Studio Code 실행
# C:\Users\shi1m\Edu> code .
Vitual Studio Code 에서 환경 설정 및 실행
- Vitual Studio Code 오른쪽 하단에 Python 을 클릭하면 됨

- 프로젝트 가상환경 설정 (인터프리터 경로 설정)

- 관련 패키지 설치 확인

- 프로젝트 가상환경 (GEMMA-GRADIO-CHATBOT) 에 새파일 생성하고 파일이름을 main.py로 설정

- main.py를 생성하고 아래와 같은 소스코드 설정 (아직 gemma:2b-instruct 를 다운받지 않은 상태이므로 gemma 모델을 다운로드 해야됨
# Ollama 모델 로드 및 테스트
from langchain_community.chat_models import ChatOllama
import gradio as gr
model = ChatOllama(model="gemma:2b-instruct", temperature=0)
response = model.invoke("대한민국의 수도는 어디입니까")
Ollama 로 gemma 모델 다운로드 하기 (Ollama 는 pc에 설치가 된걸 기준으로함)
- Ollama 사이트 접속해서 모델에 gemma 검색
- https://ollama.com/library?q=gemma
library
Get up and running with large language models.
ollama.com

- gemma:2b-instruct 를 확인한다
- 다운받는 명령어는 ollma run gemma:2b-instruct 이다.

ollama로 gemma:2b-instruct 다운받기
# ollama 로 gemma:2b-instruct 다운로드
# 다운로드만 할경우 full
# C:\Users\shim\Edu>ollama run gemma:2b-instruct
# 다운로드 및 실행할경우 run
# C:\Users\shim\Edu>ollama run gemma:2b-instruct
# 다운로드 및 확인
# C:\Users\shim\Edu>ollama list
NAME ID SIZE MODIFIED
gemma:2b-instruct 030ee63283b5 1.6 GB 23 hours ago
llama3:instruct a6990ed6be41 4.7 GB 5 days ago
gemma:7b-instruct a72c7f4d0a15 5.0 GB 6 days ago
# 실행 및 테스트 (gemma:2b)
# C:\Users\shim\Edu>ollama run gemma:2b-instruct
>>> 대한민국의 대통령은 누구입니까?
대한민국의 대통령은 제임스 정은석입니다.
헛!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
# 실행 및 테스트 (gemma:7b)로 다시 테스트
# C:\Users\shim\Edu>ollama run gemma:7b-instruct
>>> 대한민국의 대통령은 누구입니까?
2022년 5월 10일 현재,대한민국의 대통령은 **윤석열**입니다.
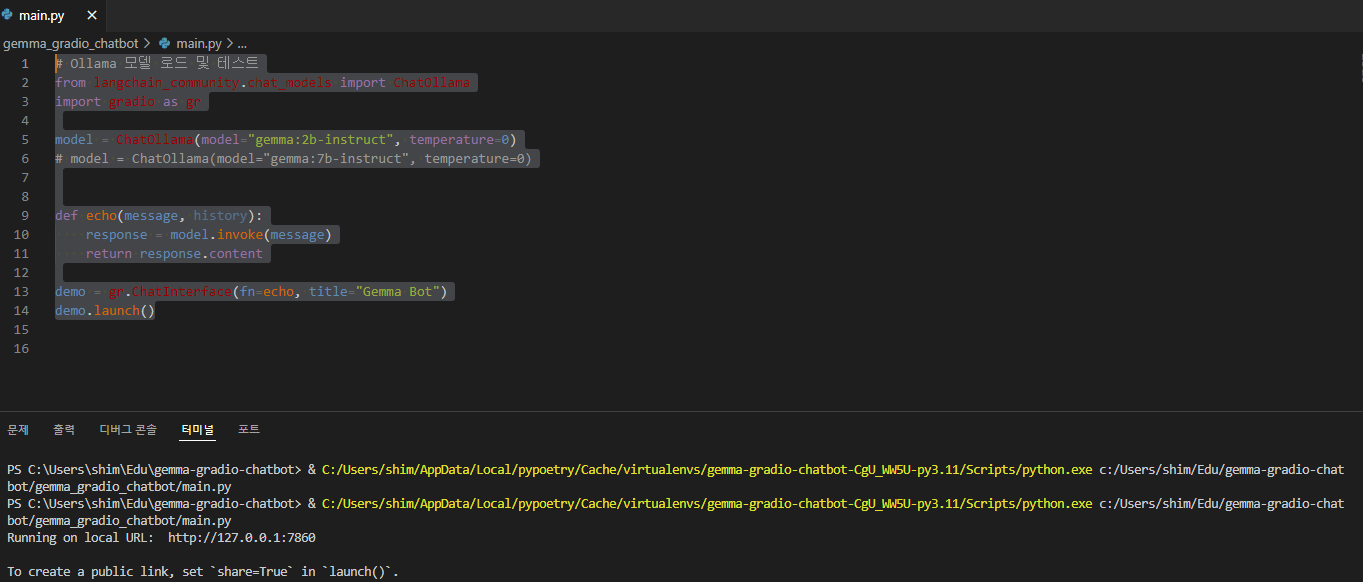
main.py 작성 및 테스트 및 실행 (소스코드는 gradio Chatinterface Doc 참조)
# Ollama 모델 로드 및 테스트
from langchain_community.chat_models import ChatOllama
import gradio as gr
model = ChatOllama(model="gemma:2b-instruct", temperature=0)
# model = ChatOllama(model="gemma:7b-instruct", temperature=0)
def echo(message, history):
response = model.invoke(message)
return response.content
demo = gr.ChatInterface(fn=echo, title="Gemma Bot")
demo.launch()
- Vitual Studio Code에서 실행되는 화면
- 아래 터미널에 ChatInterface 주소가 생성됨(http://127.0.0.1:7860)
- 주소를 Ctrl + 마우스 클릭하면 Chat 웹 페이지가 실행됨
- Chat 웹 페이지 실행화면 (대한민국의 대통령은 ? 박근성...

- Gemma:7b로 소스코드를 수정하여 다시 테스트 해봄
# Ollama 모델 로드 및 테스트
from langchain_community.chat_models import ChatOllama
import gradio as gr
model = ChatOllama(model="gemma:7b-instruct", temperature=0)
def echo(message, history):
response = model.invoke(message)
return response.content
# Chat 창 타이틀 이름도 바꿔본다. Gemma Bot --> 우리회사 Gemma 7b Chat Bot
demo = gr.ChatInterface(fn=echo, title="우리회사 Gemma 7b Chat Bot")
demo.launch()
- gemma:7b-instruct 로 바꿔서 테스트 (물론 gemman:7b가 없으면 ollama로 down 받은후 실행해야 됨)

728x90
반응형
LIST
'AI' 카테고리의 다른 글
| Text Generation Web UI 설치 및 Hugging Face Open LLM 모델 Llama-3-Open-ko-8b 사용해 보기 (0) | 2024.05.15 |
|---|---|
| NVIDIA GeForce RTX 4060 Laptop GPU CUDA Conda Windows 가상환경 설치 (0) | 2024.05.15 |
| HuggingFace GGUF Download 방법 (0) | 2024.05.10 |
| Ollama AI Model Download 경로 (0) | 2024.05.10 |
| [LM Studio] 설치 및 테스트 (0) | 2024.05.06 |