728x90
반응형
2024년 6월 기준으로 작성
LLM(Large Language Model) 개념
- LLM개념
(Google)
주어진 프롬프트에 대해 인간과 유사한 응답을 생성하기 위해 방대한 양의 텍스트 데이터로 훈련된 고급 AI 모델
입니다. 이러한 모델들은 인간 언어를 이해하고 생성하는 등 다양한 작업에서 뛰어납니다. 이로 인해 다양한 응용 분야에서 매우 가치 있는 도구로 사용될 수 있습니다.
(AI와 LLM)
AI > 머신러닝 > 인공 신경망 > 딥러닝 > Gen AI > LLM
- 대규모 언어모델에 대한 조(A Survey of Large Language Models) (https://arxiv.org/)
A Survey of Large Language Models
Language is essentially a complex, intricate system of human expressions governed by grammatical rules. It poses a significant challenge to develop capable AI algorithms for comprehending and grasping a language. As a major approach, language modeling has
arxiv.org
2303.18223v13-A Survey of Large Language Models
5.40MB
- 최근 몇 년 동안의 대규모 언어 모델의 통계
- 사전 훈련 데이터 규모(토큰 수 또는 저장소 크기), 하드웨어 리소스 비용
- Publicly Available(공개) / Closed Source(비공개) /Pre-train Data Scale(사전훈련 데이터 규모) / RLHF(인간 피드백을 통한 강화 학습)
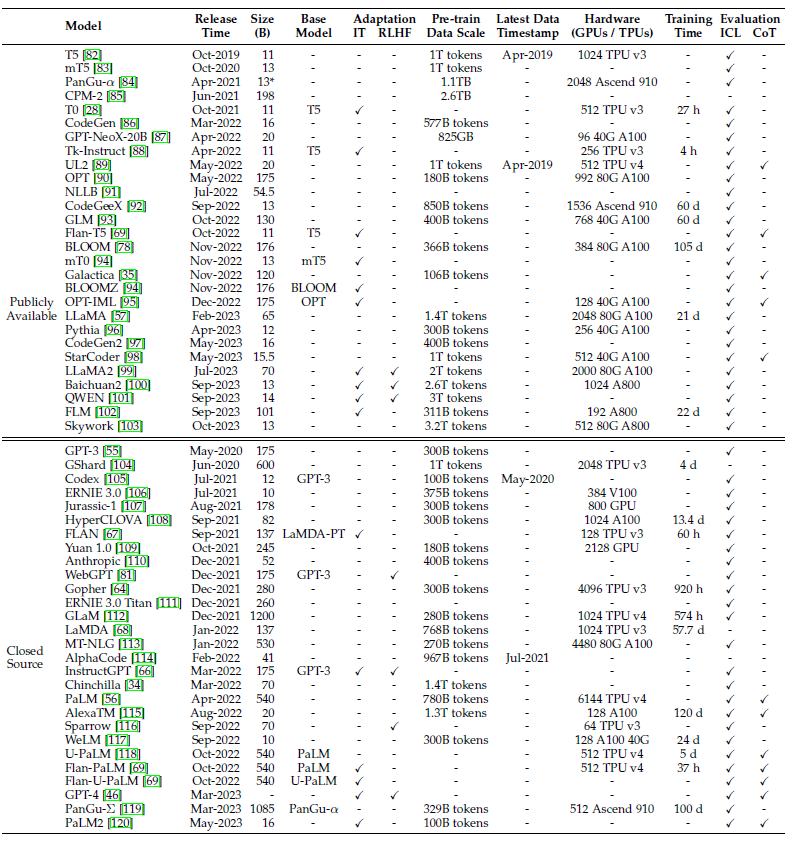
- LLM 모델 종류 (노랑색은 공개, 오픈소스)
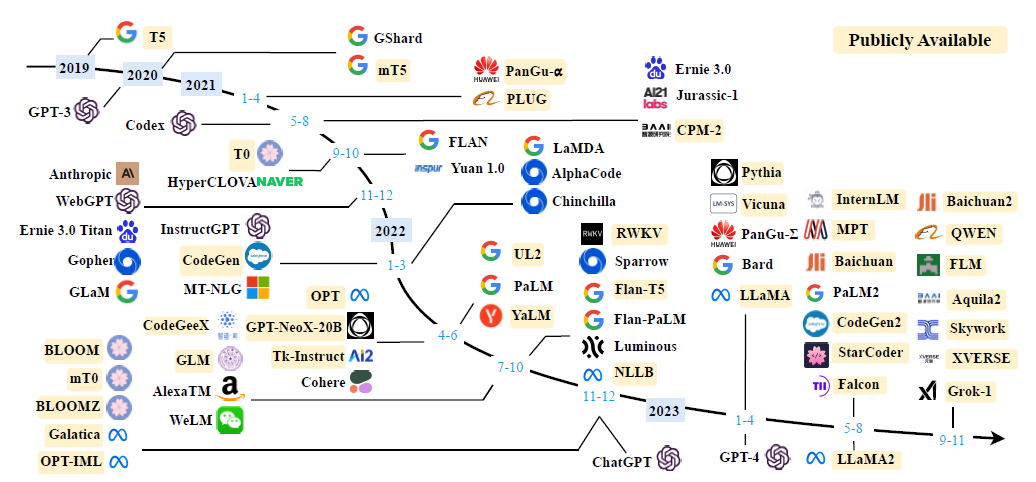
- OpenAI (GPT 발전 기준)
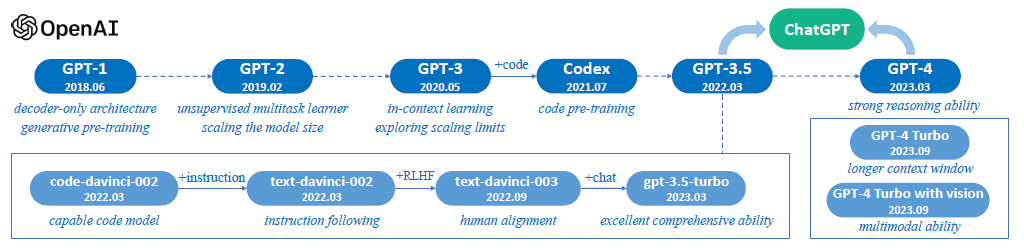
- LLM 의 종류 https://huggingface.co 참조
| 구분 | 파라미터 규모 | 비고(허깅페이스 모델 예시) |
| LLM(Language Model) | 700억개 이상 (70B) | https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct/tree/main meta-llama/Meta-Llama-3-70B-Instruct |
| SLM(Small Language Model) | 70억개 이하 (7B) | https://huggingface.co/meta-llama/LlamaGuard-7b meta-llama/LlamaGuard-7b |
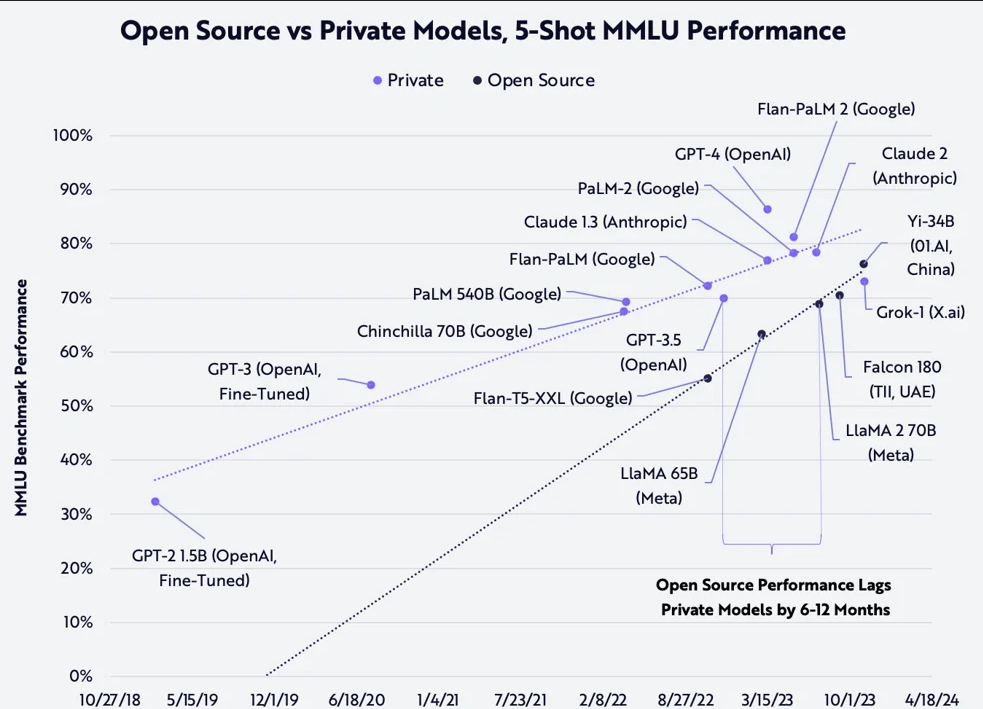
- 오픈소스와 프라이빗 모델의 MMLU 벤치마크 정확도 추이(사진 = 아크인베스트)
- 인공지능의 영역

- 여러가지 유형의 AI모델

- 국가별 AI기업

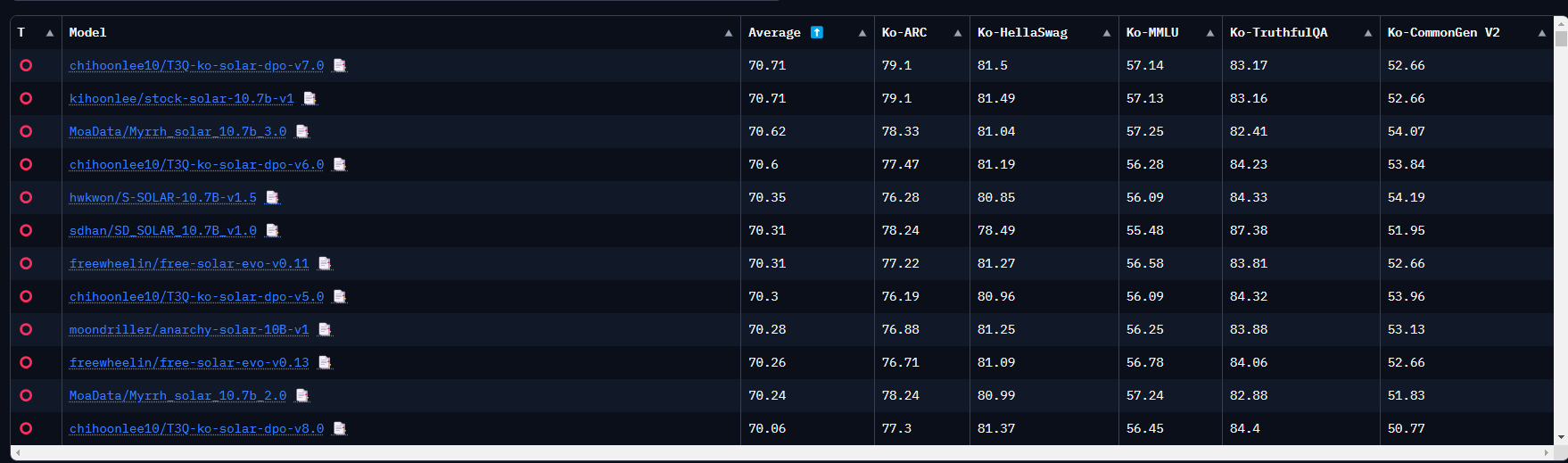
- 한국어 언어모델 순위 (Open Ko-LLM Leaderboard - HuggingFace)
- https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard
Open Ko-LLM Leaderboard - a Hugging Face Space by upstage
huggingface.co
LLM 생성과정 (추가 편집 예정)
- 데이터 수집 및 준비
- 모델 설계
- 모델 학습
- 평가 및 검증
- 배포 및 유지보수
LLM 관련 용어
- 토큰화(tokenization) : 텍스트를 작은 단위로 나누는 과정 (I am a boy!) I, am, a, boy!
- 정규화(표준화) : eat, eats, ate, eating --> eat으로 표준화화
- 모델의 실행 성능과 효율성을 향상을 위해 신경망의 가중치(weight)와 활성화 함수(activation function) 출력을 더 작은 비트 수로 표현하도록 변환하는 기술을 말한다.

LLM 활용 방법
- 파인튜닝 :
- RAG(Rettieval-Augmented Generation) :
수정중
2024.6.12
728x90
반응형
LIST
'AI' 카테고리의 다른 글
| Ollama local 모델 다운로드 및 langserve 설치 테스트 (1) | 2024.06.08 |
|---|---|
| Ollama local 모델 다운로드 및 langserve 설치 테스트 (0) | 2024.06.08 |
| Anaconda(아나콘드) conda 사용법 (1) | 2024.06.08 |
| Text Generation Web UI 설치 및 Hugging Face Open LLM 모델 Llama-3-Open-ko-8b 사용해 보기 (0) | 2024.05.15 |
| NVIDIA GeForce RTX 4060 Laptop GPU CUDA Conda Windows 가상환경 설치 (0) | 2024.05.15 |